Experience with flight data indicates that the method of maximum likelihood provides reliable gamma-ray results. See Mattox et al. (1994) for a full description for the use of likelihood for EGRET data analysis. Monte Carlo characterization of the method is in progress (Willis et al., 1993). The method allows simultaneous estimate of background model parameters (a multiplier for a diffuse galactic emission model and the intensity of isotropic emission) and the intensity of emission from a hypothetical point source distributed as the EGRET PSF.
The maximum likelihood ratio test provides a means to evaluate the strength of the evidence for the existence of a point source of gamma rays. By Wilks' theorem, -2 times the log of the maximum likelihood ratio (the likelihood of the data without a point source, or the null hypothesis, divided by the likelihood of the data with a point source which is the alternative hypothesis) is distributed as c2 with one degree of freedom (source strength at a predetermined location). If the source is not detected, the dependence of the likelihood ratio on the intensity of the hypothetical point source may be used to obtain an upper limit. The dependence of the likelihood ratio on the assumed position of the point source allows for estimation of the source position and the uncertainty of this position. In addition, estimates of the intensity of emission for sub-intervals of the EGRET energy range are used to obtain EGRET spectra.
LIKE is a Fortran program which accomplishes all the above tasks. LIKE uses the counts and exposure maps produced by the EGRET programs MAPGEN and INTMAP respectively. In addition, it uses a map of expected diffuse galactic emission (e.g., the output of the EGRET team programs GALDIF and ISODIF). All input maps are expected to be in standard FITS format. Reading and writing of FITS files uses FITSIO routines. Section 6 of this document describes some of the basic capabilities of LIKE. Before this, however, sections 2-5 will describe the theoretical basis for the LIKE algorithms as well as some technical aspects of LIKE calculations.
|
|
|
|
To convert the prediction map to counts, it is multiplied by the exposure for each pixel, Eij, to produce a predicted full resolution diffuse counts map G�ij. The LIKE program convolves this map with the appropriately calculated EGRET PSF to get the estimated diffuse galactic counts per bin
|
With the addition of the term involving the estimated extragalactic diffuse flux multiplied by the exposure, the general pixel counts model becomes
|
|
|
|
|
|
|
|
|
|
|
When estimating gm, gb, or ck, LIKE reports a 1 s uncertainty using eq. 3. Except in the case of a counts upper limit calculation, LIKE constrains all parameters to be non-negative. LIKE may also be used to estimate a source position via the downhill simplex method (again Numerical Recipes, AMOEBA code). However, the derivative is not available as an analytical expression for determining source position errors. LIKE provides the option of making a fine map of the likelihood ratio test statistic (command MF or LE, described in section 6) to estimate the source position and uncertainty.
|
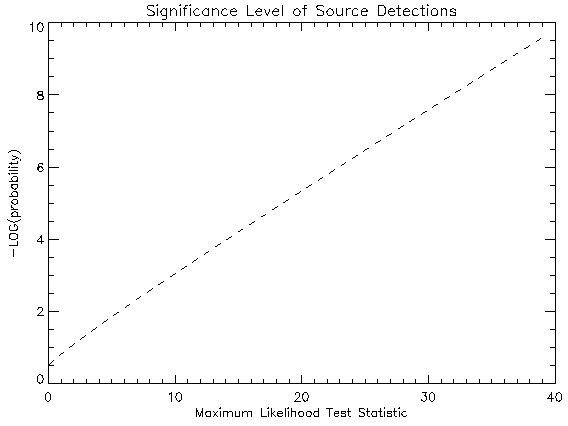
max lnLq(q � n) is the maximum value of the log of the likelihood for the null hypothesis (a model within the subspace n of Q; i.e. some parameters are restricted). The Likelihood Ratio Test statistic is especially useful because in the limit of a large number of counts (see Cash 1979 for an approximation of the distribution for small number events), the distribution of TS is c2l under the null hypothesis, where l is the difference in the number of free parameters between the alternative hypothesis, and the null hypothesis.
|
| TS | Significance | ssingle sided | sdouble sided |
| 1 | 0.32 | 0.48 | 1 |
| 2.000 | 0.1573 | 1.005 | 1.41 |
| 3.84 | 5.0×10-2 | 1.65 | 1.96 |
| 5.2 | 2.3×10-2 | 2.0 | 2.3 |
| 6.6 | 1.0×10-2 | 2.3 | 2.6 |
| 10.3 | 1.3×10-3 | 3.0 | 3.2 |
| 12 | 5×10-4 | 3.3 | 3.5 |
| 17.3 | 3.2×10-5 | 4.0 | 4.2 |
| 20 | 8×10-6 | 4.4 | 4.5 |
| 30 | 4×10-8 | 5.4 | 5.4 |
| 40 | 3×10-10 | 6.2 | 6.3 |
| 50 | 2×10-12 | 7 | 7 |
| 100 | 2×10-23 | 10 | 10 |
| 500 | 10-110 | 23 | 23 |
| 1000 | 10-219 | 32 | 32 |
| 3000 | 10-654 | 55 | 55 |
Table 5.1 Tabulation of Significance levels for some representative values of the TS.
|
|
| Figure 5.1 The pre-trials log of the significance for a restricted range of the TS. larger |
|
This may be applied to three important questions with LIKE: counts uncertainty, counts upper limit when the null hypothesis cannot be rejected, and position uncertainty determination.
|
|
| Figure 5.2 The confidence level versus h for the c22 distribution. larger |
This is a minimal set and some options may depend on other variables, but if LIKE does not find a file where it thinks it should be, the defaults can often be overridden by command line input. Properly setting these environment variables, however, will ensure that LIKE finds the proper counts, exposure, and calibration files.
The basic input to LIKE consists of standard EGRET counts and exposure maps and the EGRET calibration files. Maps up to 720 longitude and 360 latitude pixels can be used (enough for the entire sky at 0.5 degrees resolution). Note that LIKE does not do any summing of input mapfiles; co-adding maps should be done before running LIKE (e.g., using the EGRET team ADDMAP program). The standard Energy > 100 Mev maps can be retrieved by simply giving the four number viewing period (for example, period 5 � 0050). Similar shortcuts for other available maps (i.e. phase 1 total, phase 2 total, etc.) will exist. LIKE has no facility for perusing or adjusting the input maps so if one wants to print a FITS header or display a portion of the input map, use ancillary software such as the EGRET SHOW or SKYMAP programs.
The main calibration file required by like is the PSD file (Point Spread Function), although the SAR (Sensitive Area) and EDF (Energy Dispersion) files are used as well. Each calibration file contains information derived from pre-launch calibration at the Stanford Linear Accelerator Center (SLAC). For more information on EGRET calibration, refer to Thompson et. al., 1993. The PSD file contains the EGRET point spread function at 20 discrete energies, 3 azimuthal angles, and 9 inclinations. All calibration files can usually be found in the directory pointed to by the CALIB_DIR environment variable. There are several calibration files available which represent different operating conditions for the EGRET instrument, but the difference in the resulting PSF is not believed to be significant.
The actual EGRET PSF used by LIKE is constructed based upon the measured energy range of the map and will be a combination of the PSF's measured at discrete energies combined assuming a candidate source has some given power-law index, GAMMA. This also requires using the SAR and EDF calibration files since the sensitive area as a function of energy and the dispersion of measured gamma-ray energies are utilized. Averaging over inclination and azimuth are also performed. By default, the CTL file is searched for in the working directory with filename='CTL' and, if not found, a full pathname should be given. The CTL file itself sets up many LIKE parameters. The values of entries in the CTL file don't normally need to be adjusted, and if they are, should be adjusted with caution. An annotated CTL file is explained in Appendix 3.
Additional input to LIKE is the diffuse model map, necessary for the estimate of gmult, and the ancillary PSF file which is a list of EGRET sources which can be included in the analysis. LIKE will run without a diffuse model map. However, especially near the galactic plane, results will not be optimal. The input diffuse maps will note whether or not the map has already been convolved with the EGRET PSF for the appropriate energy range. The diffuse model map must match the selected energy range of the input counts map if it has been convolved with the PSF.
Once the setup stage is complete, LIKE is ready to run. The initial state of LIKE is that the Region of Interest (ROI), which is the active map area for several functions, is set to the entire map; RANAL, a critical parameter, which is the radius of analysis for determining model parameters has been input (the default is energy dependent), and g_b and g_m are set to their energy dependent initial values. The next step is to perform the analysis. Everyone using LIKE will have their own preferences and approaches to this process. There is no guide like experience! Even so, the following subsections describe a few of the major options of LIKE in a somewhat logical progression from setting up the parameters to outputting results (also see Appendix 1 for a sample LIKE session or Appendix 2 for a complete list of LIKE commands).
Two of the most fundamental adjustments are to change the ROI or the energy range. These are accomplished with the S and E commands. Changing the energy (E)will allow you to select from a different range of a multi-range FITS file or to choose a completely new map; of course, a new PSF will also be calculated at the same time. This command essentially starts the LIKE session over again as all previously performed calculations are no longer valid for the new input map. The command to define a new ROI (S) (input the defining coordinates as lower LONG, upper LONG, lower LAT, upper LAT) is less drastic. The ROI is the portion of the input map which is the area of interest for many commands which search over large areas of the map (i.e., searching for a point source with the MS command described below) and also defines the mapping region for many output functions. Note that RANAL can extend out beyond the defined ROI with those points contributing to the analysis. After adjusting the ROI, many aspects of the current analysis may still be valid, but some calculated values may need to be changed. Alternate methods for setting the ROI are that a rectangle may be selected by specifying the rectangle center and width in either direction or that the coordinates of a point and the half-width of a square about the point may be input.
Adjustments to other parameters for the current analysis are usually accomplished through the Pnn command set. These commands are quite valuable and may effect the analysis in a major way. Perhaps the two most important are PA, which adjusts the ``other PSF map'', and PR which adjusts the range for the likelihood analysis (RANAL). The radius for which data is included in the likelihood test may be as large as 180 degrees. The PSF matrix only goes to 20 degrees - data beyond 20 degrees will pertain to the determination of Gmult and Gbias only for unmodeled sources. RANAL should be large enough to include most of the EGRET PSF (which is an energy dependent value; see Thompson et. al., 1993), yet small enough to keep errors in the background model from adversely effecting the analysis. As the size of RANAL is increased, however, more data is used for estimating the model parameters decreasing statistical error. This is an example of the classic tradeoff between systematic and statistical errors in data analysis. The correct value of RANAL has not been definitively prescribed.
In some cases, the field of view may contain more than one source. The analysis may be affected by wings of the PSF from any individual source affecting the likelihood estimates for a separate candidate source. This problem can be obviated by adjusting the model to include PSF's from any nearby, known sources with the PA command. Up to 500 PSF's from known sources can be accommodated. An input catalog of source positions and counts for sources may be used. The PA command invokes the PSF_ADJ sub-menu. The sub-command I will read such a disk file, and build the OTHER PSF component of the model from this list. At this point, each new PSF is active, or included in the model. The sub-command X will delete an individual PSF. The sub-command A will add the current active psf, while the sub-command D will add a modification of the active psf. The sub-command M will toggle the psf active Mark (for LM analysis). These commands will all prove valuable in adjusting the model for multiple sources in the field-of-view before likelihood testing or parameter estimation for an unidentified source.
Also notable is the PMS command, which toggles the SPECTRAL flag on and off, also changes the value of delta_lnL used in an upper limit evaluation to 1.0 (the appropriate value for 1 sigma error estimates - corresponding to a confidence of 84% - the integral of the gaussian distribution from -� to 1 s). Delta_lnL may be changed otherwise with the PML command. If the SPECTRAL flag is true, the counts obtained in the L or LM commands are written in a format which can be directly pasted into a SPECTRAL input file. See the command summary in Appendix 2 for information on other parameters which can be adjusted.
Each parameter is estimated according to the methods described in Section 4. The user has the option of estimating each parameter individually, in pairs, or all 3 model parameters simultaneously. If a multi-parameter estimation fails to converge, the number of parameters being optimized is reduced. A warning is printed if only the reduced optimization is achieved. Turn on the verbose flag (PMV) to see exactly what transpires in such a case. Negative values of Counts, Gmult, & Gbias are not permitted. Two critical parameters are Gmult_nom, and Gbias_nom - the approximate values expected. These are used to start the Newton-Raphson method as close as possible to the optimal values in order to achieve reliable convergence. Both are set automatically upon loading a counts map, but may be changed with PMN. One can estimate any parameter with extant values of the other model parameters, or adjust the others manually. Counts units are actually an estimate of the number of photons received whereas gmult is a multiplier for the diffuse intensity model (nominally 1.0 for E > 100 MeV) and gbias is reported (or specified) in units of 10-5cm-2 s-1 sr-1 (Also nominally 1.0 for E > 100 MeV).
For example, estimation of source counts for a specific location with the extand values of gmult and gbias can be accomplished the CC command while the `C command alone allows the user to adjust gmult and gbias if desired. The CB command will evaluate counts and gbias simultaneously with a user set value of gmult while CBB will evaluate gbias and counts using the extant value of gmult. Similar commands follow for evaluating gmult and gbias, with most optimization combinations possible in the B,G,C command hierarchy (see appendix 2 for a list).
Many of these commands will output the log of the likelihood and/or inquire if a reduced likelihood source test is desired (i.e., compare lnL for an estimate of ck and gb to that of an estimate of gb only with ck=0, both estimates done with gm fixed, or conversely compare LnL for an estimate of ck and gm to an estimate of gm with ck=0, both done with gb fixed). In addition, some of these commands have counterparts that allow maps of each parameter to be produced (the M command set) as described in section 6.4. One command of note is GBC, which evaluates counts, gmult, and gbias simultaneously. The wide range of commands exist to provide as much flexibility as possible. for most EGRET analyses, the L commands pertain.
In terms of source existence, the most elementary functions and a possible starting point, are the LL and L commands which will perform a counts estimate for the extant and input position, respectively. These commands will produce full estimates of all model parameters, calculate the likelihood test statistic (i.e., compare lnL for an estimate of ck, gm, and gb to that for an estimate of gm and gb with ck = 0), calculate the gamma-ray flux, and report other relevant information. These can be followed up with a likelihood position analysis, the most fundamental of which would use the LE command which will find the location of the maximum test statistic as well as the centroid of the 95% confidence source location region, and an elliptical fit to the border of this region and plot it to the selected graphics device. LE makes the position of the maximum TS the source position for unidentified sources. In general, for unidentified sources, it is an open question as to which coordinates should be taken as the source position. Currently, the centroid is the most commonly used value.
Processing of multiple sources can be accomplished through the LM command. LM provides for an automatic iterative solution for multiple PSFs - those in the OTHER PSF map which are marked as active and can be produced or adjusted by the PA command mentioned above. The LM command is very useful when multiple sources exist in the same region. Since the counts assigned to a passive source in the OTHER PSF model affects the analysis of other sources, a simultaneous solution is required. The LM command achieves this through iterative analysis of sources in the OTHER PSF list. The LM command also allows for position analysis (invoking the same analysis as the LE command for each source), or input positions may be assumed. The output of LM to a disk file (with position analysis) is intended to be used in the creation of the EGRET team phase 1 catalog. Also, a command LC exists for an automatic analysis of all sources on the map in an input catalog. It creates a catalog of EGRET fluxes (and upper limits). The flux for sources with TS > TS_max is presented as a detection only. The flux for sources with TS_min < TS < TS_max is presented both as a detection and as an upper limit. The flux for sources with TS < TS_min is presented as an upper limit only (both TS_min and TS_max are adjustable with the PMT command). The default value TS_max is 25. The default value TS_min is 1. The upper limits are determined with a golden search for the Counts value which results in lnL falling by a value of delta_lnL from the value at Counts=0. The default value of delta_lnL is 3.92/2 corresponding to a 95% confidence level. The value of delta_lnL may be changed with the PML command.
Finally, the LP command set are also useful for estimating source positions. For instance, LPS invokes the AMOEBA search for the position which gives the maximum TS for a source. The LPO command will do this amoeba position optimization iteratively on each source marked in the OTHER PSF list until source positions stabilize. This is useful since the position assumed for a source can affect the position indicated for a nearby source. The MF command explained in the next section is also useful for position analysis.
After application of the above commands, the analysis should be fairly complete. Experimentation with the full command list shown in Appendix B is the best way to find the commands of value to each investigator. The next section describes some of the ways in which LIKE outputs the results of the analysis.
The Mx commands create FITS maps of some combination of the likelihood test statistic, g_m, g_b and counts. The maps written by these command are the same size as the ROI. Maps are written to NEWMAPFILE, GBIASFILE, or LMAPFILE depending on which option is used. These file definitions can be adjusted in the CTL file as explained in Appendix 3 or changed with the PMM command. Header information comes from the analysis or from the CTL file (i.e., site which can be changed freely). IF LMAPFILE, , GBIASFILE, or NEWMAPFILE are either '', or 'null', no map will be written. If the specified file exists, you will be asked if you want to write over it.
The MF command allows for the choice between solving for Gmult, Gbias, and Counts at each pixel in fine map, or solving for them once in the fine map center (which is much faster, and adequate unless the fine map is large or expected to have structure other than that of a single PSF at the center of the fine map). The map produced is the likelihood TS in the source region. The EGRET SKYMAP program can then be used to display the position confidence contours for these maps as discussed in section 5.2.3. The MS command results in 3 maps being written: TS in LMAPFILE, Gmult in NEWMAPFILE, and Gbias in GBIASFILE. The MG command results in 2 maps being written: counts in NEWMAPFILE, and Gmult in GBIASFILE. Finally, the MH (Map High Latitude) command has been added which calculates a TS for each pixel with a fixed Gmult. 3 maps are written: TS in LMAPFILE, Counts in NEWMAPFILE, and Gbias in GBIASFILE. Normally the MS command pertains. It results in each pixel being successively examined for the existence of a source centered on the pixel. The evidence (or TS) is saved in the LMAPFILE. Examination of the LMAP after the MS command finishes indicates possible high-energy gamma-ray sources.
The Oxx commands typically write maps or produce plots associated with the defined ROI and unlike the Mx commands include flux as a possible parameter. Exceptions are the OMG, OME, and OMC commands which simply write input maps (although PA can be used to include the ''other PSF'' map to the diffuse model before writing with the OMGx command). Also of note is the OMRx command which writes the residual - the difference between the data and the model. For OMG, the residual is normalized by the estimate of the uncertainty. On the other hand, OMRF writes the flux residual while OMRC writes the counts residual. Because of Poisson fluctuations, the OMR maps usually need to be smoothed with the SKYMAP program (e.g., a gaussian with s = 0.75 degrees) before features are apparent. The OMR function can be used to evaluate the quality of the diffuse model, and to see if correct assumptions about sources in the region have been made.
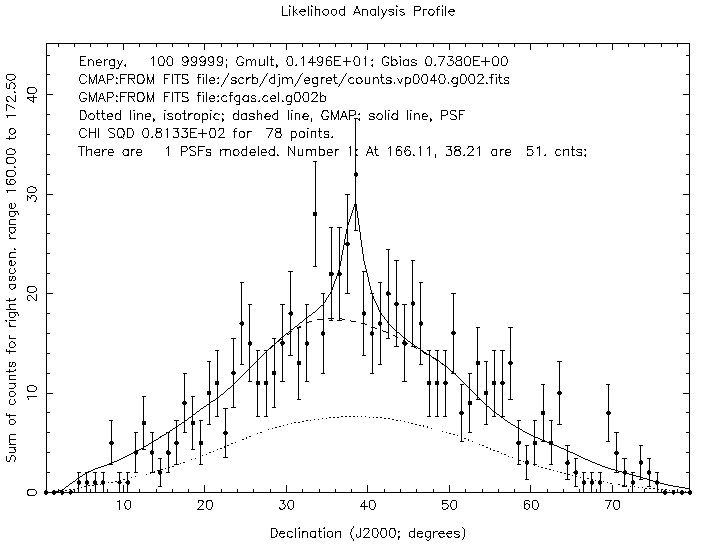
Finally, the OP profile command provides a tool similar to OMR to obtain a subjective evaluation of the quality of the fit of the model to the data. The data is compared to the model for the ROI. All 3 components of the Model are shown. The active PSF must be first added to the other PSF model in order to be shown in the profile. The data and model are summed in one dimension (nominally the smallest dimension of the ROI) and displayed as a function of the other dimension with counts displayed on the ordinate. The OP profile also calculates reduced chi-squared for the data/model comparison profiles.
Eadie et al. 1971, Statistical Methods in Experimental Physics.
Bertsch, D. L., Dame, T. M., Fichtel, C. E., Hunter, S. D., Sreekumar, P., Stacy, J. G., & Thaddeus, P., 1993, ApJ, in press.
Cash, W., 1979, ApJ, 228, 939.
Kendall, M.G., & Stuart, A. 1961, The Advanced Theory of Statistics, Volume 2, Haffner, New York.
Mattox, J.R., et al. 1994, in preparation for submission to ApJ.
Pollock, A.M., et al., 1981, AA, 94, 116.
Pollock, A.M., et al., 1985, AA 146, 352.
Thompson, D.J. et al., 1993, Ap. J. Supp., in press.
Willis, T., Mattox, J.R., et al., 1993, Proceedings of the second Compton Observatory Symposium, College Park, MD, Sept 20-22, 1993.
Press et al., 1986 Numerical Recipes.
bronco[23]like
LIKE - version 4.6
Which ctl file? (return for CTL in current directory)
Will use CTLFILE: CTL
READING CTL CARDS
Enter CMAPFILE name:counts.vp0040.g002.fits
CMAPFILEcounts.vp0040.g002.fits
MAPFILE
counts.vp0040.g002.fits
Reading file:counts.vp0040.g002.fits
--------------------------------------------------------------------------------
THERE ARE 2 IMAGES with energy ranges:
1 30 MeV - 100 MeV
2 100 MeV - 99999 MeV
WHICH DO YOU WANT?
2
Reading file:exposr.vp0040.g002.fits
--------------------------------------------------------------------------------
MPE software does not support PSF for this energy range;
PSF being generated for 100.0000 < E < 10000.00
Using CALFILEs with suffix:07
/analysis1/data/difmaps/cfgas.cel.g002b
is not installed. Will read unconvolved map.
Reading file:/analysis1/data/difmaps/gas.
--------------------------------------------------------------------------------
NO:
/analysis1/data/difmaps/gas.
Error code (N) found in LIKE ; message is:
MAPRED: MAPFILE DOESN'T EXIST
Execution continues.
Enter GMAPFILE name:cfgas.cel.g002b
Reading file:cfgas.cel.g002b
--------------------------------------------------------------------------------
Multiplying the gasmap by exposure map.
The model has already been convolved.
Input radius for analysis (Ranal, cr for 15.00):
Setting ROI to entire map:
RA. 130.2500 to 234.7500 ; Dec. 0.2500000 to
79.75000
Setting up logarithm table for likelihood.
Setting OTHER PSF map to null.
Do you want to be notified if 0.60 < Gmult < 1.30
and 0.00 < Gbias < 2.00 (cr for no)
B,C,E,G,L,M,O,P,Q,S,X,? >>
Setup has completed. We chose the map from viewing period 4.0 of
phase 1 and chose the E > 100 MeV map. Note that LIKE could not
find the diffuse map in the expected places so an alternative map file
was input. We used the default value of RANAL. Let's go right to
optimizing all source parameters for the Catalog position of MRK 421
B,C,E,G,L,M,O,P,Q,S,X,? >>gbc Input counts test point: RA (J2000) and DEC (A to abort, cr for 182.250 39.750):166.110 38.210 Input Source Name (cr for ):MRK 421 Gmult 1.496402 +/- 0.084828 Gbias 0.738028 +/- 0.051214 Counts 50.54 +/- 12.18 Corresponding flux 14.448708 +/- 3.480921 10^-8 cm^-2 s^-1 Log likelihood: -2355.10So the optimization went smoothly and flux is apparent from MRK 421. Let'ss get the maximum likelihood test statistic for the current catalog position
B,C,E,G,L,M,O,P,Q,S,X,? >>ll
--------------------------------------------------------------
Estimate of Gmult and Gbias with counts=0:
Gmult 1.851476 +/- 0.085468
Gbias 0.60170 +/- 0.05158
Log likelihood: -2368.35
--------------------------------------------------------------
Simultaneous estimate of Gmult, Gbias and Counts:
Gmult 1.496393 +/- 0.084829
Gbias 0.738041 +/- 0.051214
Counts 50.54 +/- 12.18
Log likelihood: -2355.10
Test statistic: 26.51
--------------------------------------------------------------
Name RA DEC sqrt(TS) Flux+/- 1 sigma (U.L.)
Cnts +/- 1 sigma (U.L.) Gmult Gbias Ranal Asp. EXP
lnL
MRK 421 166.11 38.21 5.1 14.449 3.481
50.54 12.18 1.496 0.738 15.0 11.0 34.98
-2355.
A test statistic of 26.51 corresponds to a probability of less
than 10-6 of the ck=0 model being true (pre-trials).
The
square root of the TS is the gaussian s so MRK 421 is detected at
the 5.1 s level. Let's see what we can find out about the source
position with the LE command.
B,C,E,G,L,M,O,P,Q,S,X,? >>le Input Finemap center RA (J2000) and DEC (A to abort, cr for 166.110 38.210): Do you want to calculate Counts, Gmult, and Gbias once at fine map center, or at each point - which takes ~10 times longer but is more accurate at edges (cr for once at map center)?When in doubt, take the default!
Enter number rows & columns in fine map (cr for 10): Enter percentage confidence for source location region (tabulated values: 50, 68, 95, 99; cr for 95%): Obtain fine map centered on 166.1100 38.21000 Solving for lnL with Counts=0 for entire fine map. Gmult 1.851461 +/- 0.085468 Gbias 0.60171 +/- 0.05158 Solving for Counts, Gmult, and Gbias to be used for entire fine map. Gmult 1.496397 +/- 0.084829 Gbias 0.738039 +/- 0.051214 Counts 50.54 +/- 12.18 Try finemap full width= 6.449052 Maximum TS = 26.50879 ; found at L= 166.1100 ; B= 38.21000 Map is too large; fraction of pixels in contour is 0.07 Obtain fine map centered on 166.5399 38.13834 Solving for lnL with Counts=0 for entire fine map. Gmult 1.901675 +/- 0.085219 Gbias 0.57720 +/- 0.05137 Solving for Counts, Gmult, and Gbias to be used for entire fine map. Gmult 1.494991 +/- 0.084595 Gbias 0.745041 +/- 0.051015 Counts 50.77 +/- 12.27 New finemap center= 166.5399 38.13834 Try finemap full width= 3.932868 Maximum TS = 27.31836 ; found at L= 166.1466 ; B= 38.53163 Map is too large; fraction of pixels in contour is 0.12 Try finemap full width= 3.096331 Maximum TS = 27.37305 ; found at L= 166.2303 ; B= 38.44798 Mean position within error region 166.3851 38.35767 Characteristic radius ( 0.7589846 ) degrees yields RMS deviation 5.5977535E-02 elipse fit (in degrees): major axis a= 0.8072745 ; minor axis b= 0.6938947 ; position angle phi= 155.6362 ; yields RMS deviation 3.9397180E-02 degrees The circle with radius Rb=sqrt(a*b)= 0.7484407 degrees yields RMS deviation 5.5825576E-02 Plot fit for elipse or circle (cr for elipse, Q to return to main menu) graphics device? (return for /XWIN ): Type <RETURN> to continue: Plot fit for elipse or circle (cr for elipse, Q to return to main menu)q
|
|
| Figure 8.1 The plot of the Likelihood statistic in the region of MRK 421 for position analysis. larger |
B,C,E,G,L,M,O,P,Q,S,X,? >>s The Region Of Interest (ROI) is a selected rectangle within the map. It is the region profiled (command OP), and the region for which each pixel is examined for a point source (with the MS command in LIKE). Note that the ROI does not influence which data is used by LIKE for a point source analysis for a specific point. This is always the region within the map within Ranal of the pixel containing the point. Current ROI is: RA. 130.2500 to 234.7500 ; Dec. 0.2500000 to 79.75000 ROI_ADJ:Q; T; center; ra1,ra2,d1,d2; .; or ?>>62 70 0 80 Error code (O) found in ROIADJ ; message is: Requested ROI not entirely within the map. Border(s) adjstd.OOPS! try again
Execution continues. RA. 130.2500 to 130.2500 ; Dec. 0.2500000 to 79.75000 ROI_ADJ:Q; T; center; ra1,ra2,d1,d2; .; or ?>> B,C,E,G,L,M,O,P,Q,S,X,? >>s Current ROI is: RA. 130.2500 to 130.2500 ; Dec. 0.2500000 to 79.75000 ROI_ADJ:Q; T; center; ra1,ra2,d1,d2; .; or ?>>162 170 0 80 Error code (O) found in ROIADJ ; message is: Requested ROI not entirely within the map. Border(s) adjstd. Execution continues. RA. 162.2500 to 170.2500 ; Dec. 0.2500000 to 79.75000 ROI_ADJ:Q; T; center; ra1,ra2,d1,d2; .; or ?>>And let's also put MRK 421 in the ``other PSF'' map so that the profile will include the MRK 421 PSF
B,C,E,G,L,M,O,P,Q,S,X,? >>pa You have elected to alter the other PSF map. The current other PSF map contains: No sources in other PSF map. PSF_ADJ:A,D,I,Q,?>>a The current other PSF map contains: # NAME POSITION CNTS Sp. I. Active 1 MRK 421 166.11 38.21 50.8 2.00 1. PSF_ADJ:A,D,I,M[n],O,Q,R[n],T,X[n],.,?>>q
|
|
| Figure 8.2 The profile plot showing the PSF at the position of MRK 421. larger |
B,C,E,G,L,M,O,P,Q,S,X,? >>op Will plot ROI: 162.25 to 170.25; and 0.25 to 79.75 OK? (cr to proceed with plot, P to adjust plot parameters, or R to return to main menu) Type <RETURN> to continue: Will plot ROI: 162.25 to 170.25; and 0.25 to 79.75 OK? (cr to proceed with plot, P to adjust plot parameters, or R to return to main menu)p graphics device? (return for /XWIN ):/ps Looks like you want to graph over latitude - OK (cr)? How many pixels to combine along abscissa (cr for 1) ? Y axis Max value? (cr -> use data) Will plot ROI: 162.25 to 170.25; and 0.25 to 79.75 OK? (cr to proceed with plot, P to adjust plot parameters, or R to return to main menu)
Looks good . . . . must be ready to publish . . . .
B,C,E,G,L,M,O,P,Q,S,X,? >>pmp publish flag set to T
Bx commands are used to evaluate Gbias.
Cxx commands are used to evaluate source counts at a specific point.
Gxx commands are used to evaluate Gmult.
Lx is for a likelihood ratio test.
Mx commands are for producing the TS.
Oxx commands are for making plots or writing maps.
Px commands adjust parameters.
HEADER Annotated control Card File for LIKE. REMARK Read as formatted input - parameters must be in correct positions. REMARK Two documentation cards follow. TITLE1 CTL cards for SOURCE:like V 4.7. TITLE2 This documentation card is not currently used. REMARK The following card has no important consequences. SITE <SITE :G> <SYSTEM:U> <EXETYP:I> REMARK Use EGRET PSF. PSM4 <PSFTYP:EGRETCAL....> REMARK EGRET PSF generation parameters. Don't change. PSM1 <PSFINC : 0.2> <PSMSZ : 81> (<=201) PSM2 <CLAT : 0.0> <PGRID : 1> SELECT2 <ITRMOD : 74> <THETA :123000000> <PHI:123> REMARK Calibration result file specification. CALSPC <Event class (curve index):1> <TASC coincidence mode:1> REMARK curve index 1 is all energy classes (2=A,3=B,4=C,5=A+C) REMARK TASC coincidence mode 1 is TASC in coincidence (0 is out) REMARK LONGBINS=1 -> map parameters will be determined from counts map MAPMTX <BINSIZE: 0.00> <LONGBINS: 1> SELECT1 <LOWLIM : 00> <HIGHLIM: 00> <GAMMA : 2.00> <RVAL :20.0> REMARK Counts map specification. REMARK 'ask' will cause the program to ask the operator for the Counts map. FILENAM <CMAPFILE :ask REMARK Exposure map specification. REMARK if EMAPFILE = 'as cnts', the map in the directory with the same REMARK number as the Counts map will be read. FILENAM <EMAPFILE :as cnts REMARK Background map specification. REMARK if GMAPFILE = null, no map will be read and the GMAP will be set to 0 REMARK 'ask' will cause the program to ask the operator for the gas map. REMARK 'standard' will cause the program to read the standard diffuse map. FILENAM <GMAPFILE :standard FILENAM <RESULTFILE:console REMARK Output map specification. FILENAM <LMAPFILE :Lmap FILENAM <GBIASFILE :Bmap FILENAM <NEWMAPFILE:newmap ENDMAP ENDALL