bexrav: reflected e-folded broken power law, neutral
medium
A broken power-law spectrum multiplied by exponential high-energy
cutoff, exp(-E/Ec), and reflected from neutral material. See Magdziarz
& Zdziarski (1995)
for details.
The output spectrum is the sum of an e-folded broken power law and the
reflection component. The reflection component alone can be obtained
for
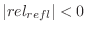 . Then the actual reflection normalization is . Then the actual reflection normalization is
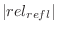 . Note that you need to change then the limits of
excluding zero (as then the direct component
appears). If . Note that you need to change then the limits of
excluding zero (as then the direct component
appears). If 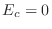 , there is no cutoff in the power law. The metal
and iron abundance are variable with respect to those set by the
command abund. The opacities are those set by the command
xsect. As expected in AGNs, H and He are assumed to be fully
ionized. , there is no cutoff in the power law. The metal
and iron abundance are variable with respect to those set by the
command abund. The opacities are those set by the command
xsect. As expected in AGNs, H and He are assumed to be fully
ionized.
The core of this model is a Greens' function integration with one
numerical integral performed for each model energy. The numerical
integration is done using an adaptive method which continues until
a given estimated fractional precision is reached. The precision can
be changed by setting BEXRAV_PRECISION eg xset BEXRAV_PRECISION 0.05. The default precision is 0.01 (ie 1%).
| par1 |
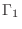 , first power law photon index , first power law photon index |
| par2 |
 , break energy (keV) , break energy (keV) |
| par3 |
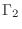 , second power law photon index , second power law photon index |
| par4 |
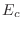 , the e-folding energy in keV (if there is no
cutoff) , the e-folding energy in keV (if there is no
cutoff) |
| par5 |
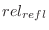 , reflection scaling factor (1 for isotropic source
above disk) , reflection scaling factor (1 for isotropic source
above disk) |
| par6 |
cosine of inclination angle |
| par7 |
abundance of elements heavier than He relative to the solar
abundances |
| par8 |
iron abundance relative to the above |
| par9 |
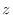 , redshift , redshift |
| norm |
photon flux at 1 keV of the cutoff broken power-law only (no
reflection) in the observed frame. |
HEASARC Home |
Observatories |
Archive |
Calibration |
Software |
Tools |
Students/Teachers/Public
Last modified: Tuesday, 28-May-2024 10:09:22 EDT
|
